事实上,不同类型的虚拟化技术是从不同的地方开始引导虚拟机系统的:
从模拟的 BIOS 开始引导的,支持 MBR、EFI、PXE 等启动方式,如 QEMU、VMWare;
从内核开始引导的,虚拟机镜像内不包含内核,如 KVM、Xen;
从 init 进程开始引导的,虚拟机是一个与主机共享内核的容器,会按照操作系统的引导过程启动各种系统服务,如 LXC、OpenVZ;
只运行一个特定的应用程序或服务的,也是基于容器,如 Docker。
/dev/kvm提供的操作包括:
• 创建一个新的虚拟机
• 向一个虚拟机中分配内存
• 读写虚拟cpu寄存器
• 向一个虚拟cpu中注入中断
• 运行一个虚拟cpu
目前主要有Intel的VT-x和AMD的AMD-V这两种技术。其核心思想都是通过引入新的指令和运行模式,使VMM和Guest OS分别运行在不同模式(ROOT模式和非ROOT模式)下,且Guest OS运行在Ring 0下。通常情况下,Guest OS的核心指令可以直接下达到计算机系统硬件执行,而不需要经过VMM。当Guest OS执行到特殊指令的时候,系统会切换到VMM,让VMM来处理特殊指令。
为弥补x86处理器的虚拟化缺陷,市场的驱动催生了VT-x,Intel推出了基于x86架构的硬件辅助虚拟化技术Intel VT(Intel Virtualization Technology)。
目前,Intel VT技术包含CPU、内存和I/O三方面的虚拟化技术。
CPU硬件辅助虚拟化技术,分为对应安腾架构的VT-i(Intel Virtualization Technology for ltanium)和对应x86架构的VT-x(Intel Virtualization Technology for x86)。
内存硬件辅助虚拟化技术包括EPT(Extended Page Table)技术。
I/O硬件辅助虚拟化技术的代表VT-d(Intel Virtualization Technology for Directed I/O)。
Intel VT-x技术解决了早期x86架构在虚拟化方面存在的缺陷,可使未经修改的Guest OS运行在特权级0,同时减少VMM对Guest OS的干预。Intel VT-d技术通过使VMM将特定I/O设备直接分配给特定的Guest OS,减少VMM对I/O处理的管理,不但加速数据传输,且消除了大部分性能开销。如下图所示。CPU硬件辅助虚拟化技术简要说明流程图:
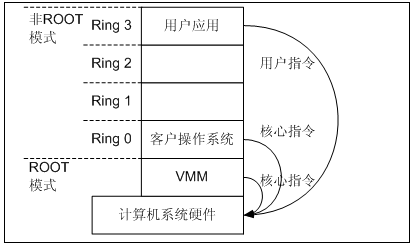
效法IBM 大型机,VT-x提供了2 个运行环境:根(Root)环境和非根(Non-root)环境。根环境专门为VMM准备,很像原来没有VT-x 的x86,只是多了对VT-x 支持的几条指令。非根环境作为一个受限环境用来运行多个虚拟机。
如上图所示,根操作模式与非根操作模式都有相应的特权级0至特权级3。VMM运行在根模式的特权级0,GuestOS的内核运行在非根模式的特权级0,GuestOS的应用程序运行在非根模式的特权级3。运行环境之间相互转化,从根环境到非根环境叫VMEntry;从非根环境到根环境叫VMExit。VT-x定义了VMEntry操作,使CPU由根模式切换到非根模式,运行客户机操作系统指令。若在非根模式执行了敏感指令或发生了中断等,会执行VMExit操作,切换回根模式运行VMM。
根模式与非根模式之问的相互转换是通过VMX操作实现的。VMM 可以通过VMXON 和VMXOFF打开或关闭VT-x。如下图所示:

VMX操作模式流程:
1)、VMM执行VMXON指令进入VMX操作模式。
2)、VMM可执行VMLAUNCH指令或VMRESUME指令产生VM Entry操作,进入到Guest OS,此时CPU处于非根模式。
3)、Guest OS执行特权指令等情况导致VMExit的发生,此时将陷入VMM,CPU切换为根模式。VMM根据VMExit的原因作出相应处理,处理完成后将转到2),继续运行GuestOS。
4)、VMM可决定是否退出VMX操作模式,通过执行VMXOFF指令来完成。
为更好地支持CPU虚拟化,VMX新定义了虚拟机控制结构VMCS(Virtual Machine ControlStructure)。VMCS是保存在内存中的数据结构,其包括虚拟CPU的相关寄存器的内容及相关的控制信息。CPU在发生VM Entry或VMExit时,都会查询和更新VMCS。VMM也可通过指令来配置VMCS,达到对虚拟处理器的管理。VMCS架构图如下图所示:
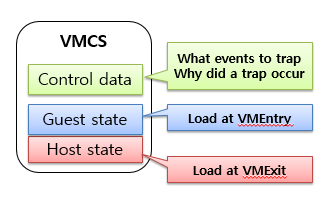
每个虚拟处理器都需将VMCS与内存中的一块区域联合起来,此区域称为VMCS区域。对VMCS区域的操纵是通过VMCS指针来实现的,这个指针是一个指向VMCS的64位的地址值。VMCS区域是一个最大不超过4KB的内存块,且需4KB对齐。
VMCS区域分为三个部分:
偏移0起是VMCS版本标识,通过不同的版本号,CPU可维护不同的VMCS数据格式;
偏移4起是VMX中止指示器,在VMX中止发生时,CPU会在此处存入中止的原因;
偏移8起是VMCS数据区,这一部分控制VMX非根操作及VMX切换。
VMCS 的数据区包含了VMX配置信息:VMM在启动虚拟机前配置其哪些操作会触发VMExit。VMExit 产生后,处理器把执行权交给VMM 以完成控制,然后VMM 通过指令触发VMEntry 返回原来的虚拟机或调度到另一个虚拟机。
VMCS 的数据结构中,每个虚拟机一个,加上虚拟机的各种状态信息,共由3个部分组成,如之前的VMCS架构图所示:
1) Gueststate:该区域保存了虚拟机运行时的状态,在VMEntry 时由处理器装载;在VMExit时由处理器保存。它又由两部分组成:
Guest OS寄存器状态。它包括控制寄存器、调试寄存器、段寄存器等各类寄存器的值。
Guest OS非寄存器状态。用它可以记录当前处理器所处状态,是活跃、停机(HLT)、关机(Shutdown)还是等待启动处理器间中断(Startup-IPI)。
2) Hoststate:该区域保存了VMM 运行时的状态,主要是一些寄存器值,在VMExit 时由处理器装载。
3) Control data:该区域包含几部分数据信息,分别是:
虚拟机执行控制域(VM-Execution control fields)。VMM 主要通过配置该区域来控制虚拟机在非根环境中的执行行为。基于针脚的虚拟机执行控制。它决定在发生外部中断或不可屏蔽中断(NMI)要不要发生VMExit。基于处理器的虚拟机执行控制。它决定虚拟机执行RDTSC、HLT、INVLPG 等指令时要不要发生VMExit。
VMExit 控制域(VMExit control fields)。该区域控制VMExit 时的行为。当VMExit 发生后处理器是否处于64 位模式;当因为外部中断发生VMExit 时,处理器是否响应中断控制器并且获得中断向量号。VMM 可以用它来定制当VMExit 发生时要保存哪些MSR 并且装载哪些MSR。MSR是CPU的模式寄存器,设置CPU的工作环境和标识cpu的工作状态。
VMEntry 控制域(VMEntry control fields)。该区域控制VMEntry 时的行为。它决定处理器VMEntry 后是否处于IA-32e 模式。与VMExit 的MSR控制类似,VMM 用它来定制当VMEntry 发生时要装载哪些MSR。VMM 可以配置VMEntry 时通过虚拟机的IDT向其发送一个事件。在此可以配置将使用IDT 的向量、中断类型(硬件或软件中断)、错误码等。
VMExit 信息域(VMExit information fields)。该只读区域包括最近一次发生的VMExit 信息。试图对该区域执行写操作将产生错误。。此处存放VMExit 的原因以及针对不同原因的更多描述信息、中断或异常向量号、中断类型和错误码、通过 IDT 发送事件时产生的VMExit 信息、指令执行时产生的 VMExit 信息。
有了VMCS结构后,对虚拟机的控制就是读写VMCS结构。后面对vCPU设置中断,检查状态实际上都是在读写VMCS数据结构。
我们在上面小节介绍了 Intel 的硬件辅助虚拟化技术,那么 AMD 的硬件辅助虚拟化技术又有什么特点呢?AMD 从 2006 年便开始致力于硬件辅助虚拟化技术的研究,AMD-V全称是AMD Virtualization,AMD-V从代码的角度分别称为 AMD和 SVM,AMD开发这项虚拟化技术时的内部项目代码为Pacifica,是AMD推出的一种硬件辅助虚拟化技术。
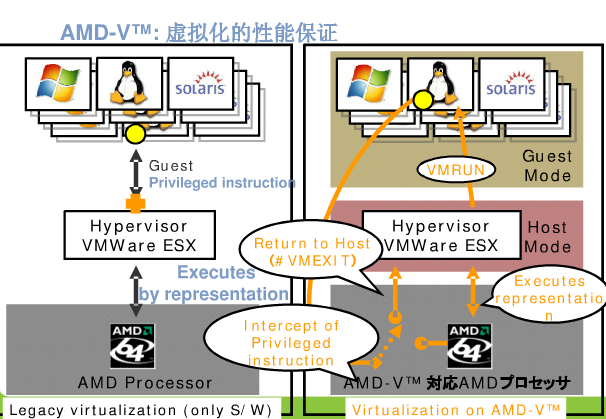
Intel VT-x 和 AMD-V 提供的特征大多功能类似,但名称可能不一样,如 Intel VT-x 将用于存放虚拟机状态和控制信息的数据结构称为 VMCS, 而 AMD-V 称之为VMCB; Intel VT-x 将 TLB 记录中用于标记 VM 地址空间的字段为 VPID, 而AMD-V 称之为 ASID; Intel VT-x 将二级地址翻译称之为 EPT, AMD 则称为 NPT,等等一些区别。尽管其相似性,Intel VT-x 和 AMD-V 在实现上对 VMM 而言是不兼容的。
AMD-V 在 AMD 传统的x86-64 基础上引入了“guest”操作模式。“guest”操作模式就是 CPU 在进入客操作系统运行时所处的模式。 “guest”操作模式为客操作系统设定了一个不同于 VMM 的运行环境而不需要改变客操作系统已有的 4 个特权级机制,也就是说在“guest”模式下,客操作系统的内核仍然运行在 Ring 0, 用户程序仍然在 Ring 3。 裸机上的操作系统和 VMM 所在的操作模式依然和传统的 x86 中一样,且称之为“host”操作模式。 VMM 通过执行 VMRUN 指令使CPU 进入“guest”操作模式而执行客操作系统的代码; 客操作系统在运行时,遇到敏感指令或事件,硬件就执行 VMEXIT 行为,使 CPU 回到“host”模式而执行 VMM 的代码。 VMRUN 指令运行的参数是一个物理地址指针,其指向一个 Virtual Machine Control Block (VMCB) 的内存数据结构, 该数据结构包含了启动和控制一个虚拟机的全部信息。

“guest”模式的意义在于其让客操作系统处于完全不同的运行环境,而不需要改变客操作系统的代码。“guest”模式的设立在系统中建立了一个比 Ring 0 更强的特权控制,即客操作系统的 Ring 0 特权必须让位于 VMM 的 Ring 0 特权。客操作系统上运行的那些特权指令,即便是在 Ring 0 上也变的可以被 VMM 截取的了,“Ring Deprivileging”由硬件自动搞定。此外,VMM 还可以通过 VMCB 中的各种截取控制字段选择性的对指令和事情进行截取,或设置有条件的截取,所有的敏感的特权或非特权指令都在其控制之中。
VMCB 数据结构主要包含如下内容 :
1. 用于描述需要截取的指令或事件的字段列表。其中 :
2 个 16 位的字段用于控制对 CR 类控制寄存器读写的截取
2 个 16 位的字段用于控制对 DR 类调试寄存器的读写的截取
一个 32 位的字段用于控制 exceptions 的截取
一个 64 位的字段用于控制各种引起系统状态变化的事件或指令的截取,如 INTR, NMI, SMI 等事 件, HLT, CPUID,INVD/WBINVD,INVLPG/INVLPGA,MWAIT 等指令, 还包括两位分别标志是否对 IO 指令和 MSR 寄存器的读写进行控制
指向IO端口访问控制位图和MSR读写控制位图的物理地址指针字段。该位图用于差别性地控制虚拟机对不同的 IO 端口和 MSR 寄存器进行读写访问。
描述虚拟机CPU状态的信息。包含除通用寄存器外的大部分控制寄存器,段寄存器,描述符表寄存器,代码指针等。 RAX 寄存器也在其中,因为 RAX 在 VMM 执行 VMRUN 时是用来存放VMCB 物理地址的。 对于段寄存器,该信息中还包含段寄存器对应的段描述符,也就那些传统 x86 上对软件隐藏的信息。
对虚拟机的执行进行控制的字段。主要是控制虚拟机中断和 NPT 的字段。
指示虚拟机进入“guest”模式后要执行的行动的字段。包括用来描述 VMM 向虚拟机注入的中断或异常的信息的字段。 注入的中断或异常在 VMRUN 进入“guest”模式后立即执行,就象完全发生在虚拟机内一样。
提供VMEXIT信息的字段。包括导致 VMEXIT 的事件的代码,异常或中断的号码,page fault 的线性地址,被截获的指令的编码等。
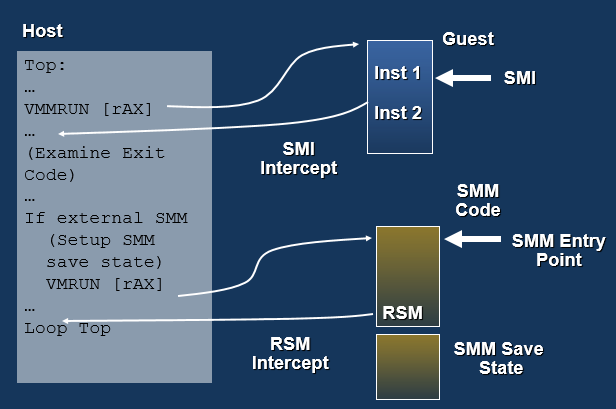
VMCB 以及其涉及的控制位图,完全通过物理地址进行指向,这就避免了“guest”和“host”模式切换的过程依赖于“guest”空间的线性地址 ( 传统操作系统内用户空间到内核的切换确实依赖于 IDT 中提供的目标的线性地址 ),使得 VMM 可以采用和客操作系统完全不同的地址空间。
VMCB 的内容在物理上被分成了俩部分,其中用于保存虚拟机 CPU 状态的信息占据 2048 字节的后半部分,我们可称之为 VMCB.SAVE; 其他信息,占据前 1024 字节范围,我们可称之为 VMCB.CONTROL。
VMRUN 命令以 VMCB 为参数,使CPU 进入“guest”状态, 按 VMCB.SAVE 的内容恢复虚拟机的 CPU 寄存器状态,并按 VMCB.SAVE 中 CS:RIP 字段指示的地址开始执行虚拟机 的代码, 并将之前 VMM 的 CPU 状态保存在MSR_VM_HSAVE_PA 寄存器所指向的物理内存区域中。VMRUN 所保存的 VMM 的 CPU状态的 CS:RIP 实际上就是 VMM 的代码中 VMCB 的下一个指令,当虚拟机因某种原因而导致 #VMEXIT 时,VMM 会从 VMRUN 后的一条指令开始执行。CPU 执行 #VMEXIT 行为时,会自动将虚拟机的状态保存到 VMCB.SAVE 区,并从 MSR_VM_HSAVE_PA 指定的区域加载 VMM 的 CPU 状态。
VMLOAD 和 VMSAVE 指令是对 VMRUN 的补充,他们用来加载和恢复一些并不需要经常使用的 CPU 状态,如 FS, GS, TR, LDTR 寄存器以及其相关的隐含的描述符寄存器的内容,VMLOAD 和 VMSAVE 可以让 VMM 的实现对“guest”进入和退出的过程进行优化,让多数情况下只使用 VMRUN 进行最少的状态保存和恢复。
VMMCALL 指令是 AMD-V 为客操作系统内核提供的明确的功能调用接口,类似于 syscall 指令 ( 从 Ring3 到 Ring 0), VMMCALL 让客操作系统直接执行 #VMEXIT 而进入 VMM,请求VMM 的服务。
回顾一下CPU虚拟化技术的实现,纯软件的CPU虚拟化使用了陷入-模拟的模式来模拟特权指令,而在x86架构中由于只能模拟特权指令,无法模拟某些敏感指令而无法实现完全的虚拟化。(在x86架构中,特权指令一定是敏感指令,但是敏感指令比特权指令多,造成某系敏感指令不是特权指令而无法模拟,使得CPU虚拟化异常),而硬件辅助虚拟化引入了根模式(root operation)和非根模式(none-root operation),每种模式都有ring0-3的四级特权级别。所以,在硬件辅助虚拟化中,陷入的概念实际上被VM-EXIT操作取代了,它代表从非根模式退出到根模式,而从根模式切换到非根模式是VM-Entry操作。
在2003年出现的Xen,使用了另外的一种半虚拟化的方案来解决x86架构下CPU的敏感指令问题。主要采用Hypercall技术。Guest OS的部分代码被改变,从而使Guest OS会将和特权指令相关的操作都转换为发给VMM的Hypercall(超级调用),由VMM继续进行处理。而Hypercall支持的批处理和异步这两种优化方式,使得通过Hypercall能得到近似于物理机的速度。
对于x86体系结构CPU,Xen使用超级调用来替换被监控的操作,其中包括x86架构下的敏感指令。Xen所采用的超级替换的方法是一种全新的设计理念:它将问题的中心,由VMM移向Guest OS自身,通过主动的方式由Guest OS去处理这些指令,而不是被移交给VMM做处理,在这种设计理念下,修改Guest OS内核。
能修改Guest OS是半虚拟化的一个技术核心。通过修改Guest OS的内核。使Guest OS明确知道自己是运行在1环上,而不是通常OS的0环,有效的避免了虚拟化的执行冲突问题。Guest OS也清楚VMM给自己提供了一个虚拟的寄存器组,并能通过其他方式去访问他们,避免了访问冲突的问题。
解决了敏感指令问题只是解决了x86架构下的半虚拟化的第一步。运行在1环的操作系统没有权限执行的指令,交给0环的VMM来处理,这个很大程度上与应用程序的系统调用很类似:系统调用的作用是把应用程序无权执行的指令交给操作系统完成。因此,Xen向Guest OS提供了一套“系统调用”。以方便Guest OS调用,这部分”系统调用“就是超级调用Hypercall。
超级调用Hypercall的机制使用,不仅使x86架构的指令虚拟化得以实现,也为后面的内存虚拟化和I/O虚拟化提供了新的思路和方法,超级调用和事件通道是整个半虚拟化的基础。
下面我们来看看半虚拟化情况下整体的访问流程图,如图所示。
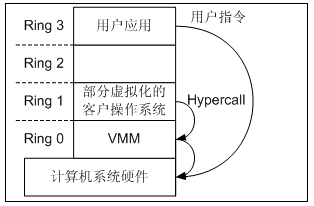
CPU半虚拟化技术
上图明确的显示了Hypercall的调用位置,在Xen中,各组件通信方式如下所示,Hypercall的调用性质是同步的。其他Xen的通信方式几乎都是异步的。

其中,在虚拟机和Xen的通信过程中,如果虚拟机需要调用敏感指令,会主动向虚拟机监控器发起Hypercall调用。Hypercall就如同传统操作系统下的系统调用,监管程序通过它向其上各虚拟机提供各种服务,如MMU 更新、Domain0 操作请求和虚拟处理器状态等。
下图显示了半虚拟化模式下的特权模式:
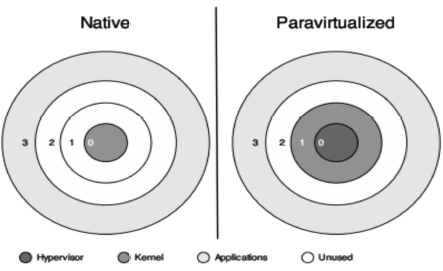
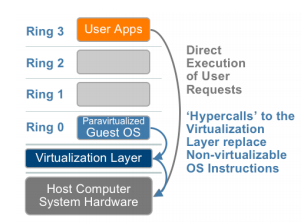
在x86架构下,原生系统和半虚拟化环境下存在差异。原生环境下,CPU有4个特权级(ring0--ring3),操作系统是处于最高级别的ring0,应用程序处于最低级别的ring3。而在半虚拟化环境下,虚拟机监视器是处于最高级别的ring0,操作系统是处于中级级别的ring1,应用程序处于最低级别的ring3。
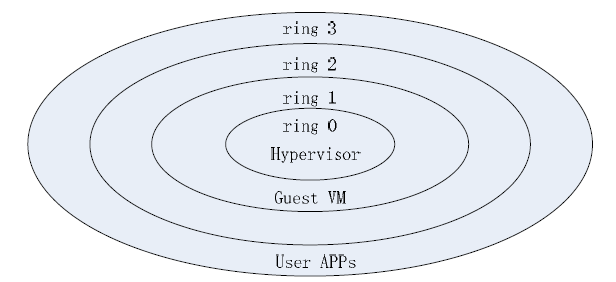
只有特权级别为1 的代码(准虚拟化Guest VM 的内核)才能向Xen 发送Hypercall 请求,以防止应用程序(特权级3)的错误调用导致对系统可能的破坏。因此,只有运行在特权级1 的虚拟机操作系统内核才能申请Hypercall。但是,一些Xen 专用的特别程序,如xend 或xe也需要有Hypervisor 的服务来完成特殊的操作,如生成一个新的GuestVM 等,这在Xen Linux 中是通过一个称为privcmd 的内核驱动程序实现。应用程序通过ioctl 向该驱动程序提出服务请求,运行在虚拟机内核(特权级1)的privcmd 驱动程序再将服务请求以Hypercall 形式转向Hypervisor,并由后者真正完成生成新Guest VM 的动作。
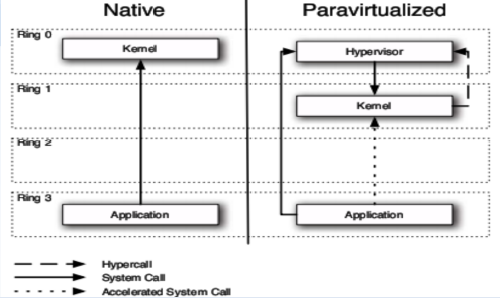
上图中显示了Hypercall所在的位置,Hypercall位于图中右上方,内核向Hypervisor发起调用的哪里。Xen启用130号中断向量端口(十六进制的82H)作为超级调用的中断号。这一个中断向量的DPL被设置为类型为1,类型为中断门。这样,超级调用能够由处于特权级1的客户机操作系统发起,而不能从用户态发起。
另外,在x86指令集的指令中,有17 条指令不能有效的在ring 1 特权级上运行,Hypercall 的存在解决了这些指令不能正常执行的问题。
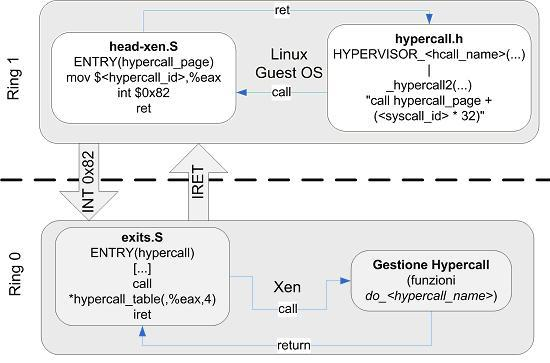
Hypercall 机制中,在32 位x86 架构下,Hypercall 通过int0x82陷阱(Trap)指令实现,因为传统操作系统本身并不使用int0x82 (Linux 使用int 0x80 作为系统调用指令,int 0x82 并未使用)。
int0x82包括:
超级调用号:xen/include/public/xen.h中定义了45个超级调用,其中有7个是平台相关调用。
超级调用表:xen/arch/x86/x86_32/entry.S中定义了超级调用表,通过超级调用号索引就可以方便的找到对应的处理函数。
超级调用页:超级调用页是Xen为Guest OS准备的一个页,可以做到不同Guest OS有不同的超级调用页内容。
Hypercall 的具体功能识别号由eax 表明,而其他参数则在ebx, ecx, edx, esi 和edi 中。为了减少虚拟机和Hypervisor 之间的特权级别(Ring)切换次数,Xen 提供对Hypercall的批处理,即将几个Hypercall 功能请求放在一个列表中由专门的Hypercall 批处理请求完成。在Xen 中,系统调用表与Hypercall 表都在entry.S 文件中被定义。
x86 硬件支持 4 个特权级 (Ring),一般内核运行在 Ring 0, 用户应用运行在 Ring 3, 更小的 Ring 有比更高的 Ring 能访问更多的系统全局资源,即更高的特权。有些指令只能在 Ring 0 才能正确执行,如 LGDT、LMSW 指令,我们称之为特权指令;另外有些指令可以在 Ring 3 正确执行,如 SGDT、 SMSW、PUSHF/POPF,我们称之为非特权指令。
正常模式和虚拟化两种情况叙述下,特权模式说明如下:
正常模式:特权级别是针对段来讲的,段描述符的最后两位标识了该段所位于的特权级别,比如,中断处理程序运行于ring0(),此时的内核程序是具有特权的,即ring0。位于ring3用户程序可以通过系统调用的方式,int80,后特权翻转入ring0,然后就可以顺利执行中断处理程序(好像是用户程序调用内核程序的唯一途径)。
虚拟化情况下:
特权解除:是指解除正常情况下运行于ring0的段,比如中断处理程序,为了虚拟化需要,此时解除其特权,将其运行于ring1。当用户程序通过系统调用时,其跳转到的中断处理程序运行于ring1。但是,在中断处理程序中,有部分指令是必须在ring0才能执行的,此时,便会自动陷入,然后模拟。也就是说,用户程序运行特权指令,会有两次特权下降,一次是通过系统调用进入ring1,第二次是通过特权指令陷入进入ring0。这说明,中断发生时的中断处理程序还是以前的位于内核的代码,但是其运行级别为ring1,部分指令还需要再次陷入,才能执行。另外,还有一个重要问题,就是部分敏感非特权指令无法陷入的问题:存在二进制翻译、超级调用等方式,强迫其陷入,然后模拟。
在传统的 X86 平台上支持虚拟化上存在如下问题 :
X86 指令集中存在 17 条敏感的非特权指令,“非特权指令”表明这些指令可以在 x86 的 ring 3 执行, 而“敏感性”说明 VMM 是不可以轻易让客操作系统执行这些指令的。 这 17 条指令在客操作系统上的执行或者会导致系统全局状态的破坏,如 POPF 指令,或者会导致客操作系统逻辑上的问题,如 SMSW 等读系统状态或控制寄存器的指令。传统的 X86 没法捕获这些敏感的非特权指令。
除了那 17 条敏感的非特权指令,其他敏感的指令都是敏感的特权指令。在 x86 虚拟化环境,VMM 需要对系统资源进行统一的控制,所以其必然要占据最高的特权级,即 Ring 0, 所以为了捕获特权指令,在传统 x86 上一个直接可行的方法是 “Ring deprivileging”, 如将客操作系统内核的特权级从 Ring 0改为 Ring 1 或 Ring 3, 即 “消除” 客内核的特权,以低于 VMM所在的 Ring 0, 从而让 VMM 捕获敏感的特权指令。
半虚拟化的思想就是,让客户操作系统知道自己是在虚拟机上跑的,工作在非ring0状态,那么它原先在物理机上执行的一些特权指令,就会修改成其他方式,这种方式是可以和VMM约定好的,这就相当于,通过修改代码把操作系统移植到一种新的架构上来,就像是定制化。所以XEN这种半虚拟化技术,客户机操作系统都是有一个专门的定制内核版本,和x86、mips、arm这些内核版本。这样以来,就不会有捕获异常、翻译、模拟的过程了,性能损耗非常低。这就是XEN这种半虚拟化架构的优势。这也是为什么XEN半虚拟化只支持虚拟化Linux,无法虚拟化windows原因,微软不修改代码无法实现半虚拟化。